how i'm cherry-picking claude code skills that i actually need
How I curated 71 Claude Code skills out of a noisy plugin marketplace, why I track every install with origin.md, and how I generate new skills without polluting my catalog.
filed under #claude-code · #skills · #ai-orchestration · #tooling
I have 71 skills in my Claude Code right now. 30 of them are forks of public skills, adapted to fit my workflow. 20 are public skills I kept unchanged. 21 I wrote myself for things nobody else's skill covered. Total: 71 deliberate choices, each with a reason.
That number used to be much higher. Most of what I removed wasn't bad. It just wasn't mine.
This post is how I got here.
The plugin problem
Plugins for Claude Code launched in October 2025. The unit of distribution is a plugin: a package that bundles multiple skills, plus optional hooks and MCP server configs, behind a single name. You install a plugin from a marketplace with /plugin install <name>@<marketplace>.
When I first wanted Anthropic's frontend-design skill, I ran /plugin marketplace add anthropics/skills. At the time, there was no per-plugin or per-skill install path. Adding the marketplace dropped the entire repo of official Anthropic skills into my .claude/. So 20-something skills landed alongside the one I asked for.
The next day I was generating a weekly status report for a client. Halfway through, gif-creator fired on something in the report and embedded a small animated memo into the document. I didn't notice. The client noticed it on our weekly call. We laughed.
That was the motivator. The marketplace had no way to give me three skills out of twenty. The mental model of "user" the plugin was designed around wasn't mine. Most of those skills had nothing to do with the work I actually do.
Three things were true at once:
- Plugins ship as packages. You take the whole package or you don't get the one skill you wanted.
- Once installed, you don't control when skills trigger. They fire on whatever phrasing the original author wired in, not on phrasing that maps to your work.
- There's no quality signal post-install. Skills don't have ratings or download counts the way npm packages do. You only find out a skill is wrong for you when it fires at the wrong moment.
It's better today. The marketplace now supports per-plugin install, so you can opt into a smaller bundle rather than the entire repo. That helps. It still doesn't let you opt into individual skills, and once a plugin lands, the trigger phrasing is whatever the author wrote. The packaging model is fine for distribution. It's just not how I want my own catalog to look.
Skills aren't always isolated
Here's the deeper version of the same problem.
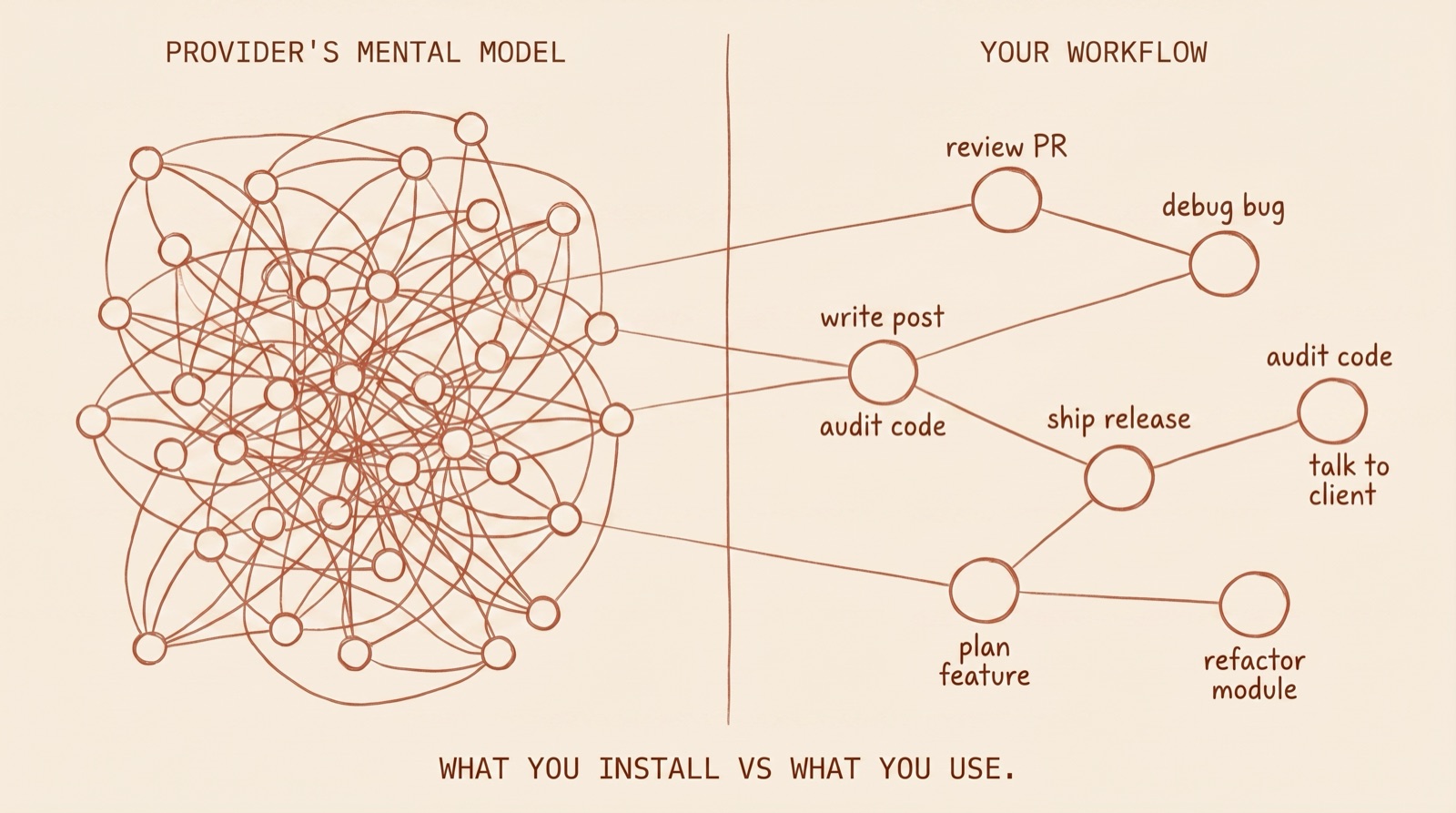
Skills aren't always isolated. Many of them reference each other. Skill A triggers, references skill B in its body, which loads docs that reference skill C. The reference chain is invisible from the outside, and even when the chain fires, it doesn't fire the way you want it to.
Those reference graphs were built around the provider's mental model of how someone like you works. Your workflow is a different graph, with different nodes and different edges. You review PRs differently than the skill author imagined. You debug bugs in a sequence that doesn't match the agent the author wired together.
Without intervention, you adopt the provider's graph by default and your skills fight your actual workflow. This is the same problem as inheriting a 50,000-line codebase from a previous agency. The structure was built around someone else's mental model. Rewriting it is the only sane option short of starting fresh.
skills are forks, not extensions. Forks need receipts.
My answer
Two parts.
The first is to stop installing whole plugins. I want to pick the skills I actually need before they hit my .claude/. I built a small skill called selective-plugin for that. It lists every asset in a marketplace plugin (skills, agents, hooks, commands), lets me check the boxes I want, and skips the ones I don't.
The second is to track every install. Every skill that lands in my catalog gets an origin.md next to its SKILL.md recording where it came from, what I changed, and how to refresh it from upstream without losing my changes. selective-plugin writes that origin.md for me at install time so the audit trail starts immediately, not retroactively.
That's the framework. Selective import plus per-skill provenance. The rest of this post is the implementation: how origin.md actually looks, how I generate new skills now, and one skill I built that's earning its keep.
selective-plugin: importing one skill at a time
selective-plugin lists everything inside a marketplace plugin and lets you choose individual assets. You add the marketplace the normal way with /plugin marketplace add <repo>, then invoke selective-plugin with the plugin name. It walks the plugin tree, prints every skill, agent, hook, and command, and asks which ones you actually want. Only the boxes you check land in .claude/.
What it does that the standard install doesn't:
- Lists every asset in the plugin before installing any of them
- Lets you pick by skill name, not by plugin
- Auto-creates an
origin.mdnext to each installed skill, prefilled with the source repo URL, the original SKILL.md path, and the fetch date
That last one is the one I care about most. The audit trail starts at the install. I don't have to remember six months later where a skill came from, because the receipt is right next to the skill.
The skill is not fancy. It's about 200 lines of bash and markdown. I built it because I wanted three skills out of a 20-something-skill plugin and the marketplace UI had no way to give me just three.
origin.md: the missing metadata layer
30 of my 71 skills have an origin.md next to their SKILL.md. 20 are public skills I kept unchanged (no origin.md needed - the upstream IS the receipt). 21 I wrote myself.
The schema is structured around the idea that every skill is a fork of someone else's mental model. Every fork needs receipts. Here's what an origin.md looks like:
# Skill Origin
## Source
- **Repository:** https://github.com/...
- **Original SKILL.md:** https://github.com/.../SKILL.md
- **Upstream references:** https://github.com/.../references
- **Fetched:** YYYY-MM-DD
- **Note:** (optional) deprecated upstream, blog post link, alternative sources
## Changes from Original
### Upstream files taken as-is
- file1.md
- file2.md
### Upstream files modified
- filename - rewrote X to do Y because Z
- LICENSE.txt
### Custom additions
- capability X added because real-world need Y
- reference file Z added (not in upstream)
### Cherry-picks from later upstream versions
- YYYY-MM-DD upstream v0.X.Y: pulled additive changes A, B, C
- did NOT adopt: rewrite to stub style (incompatible with offline use)
### Excluded from upstream and why
- templates/ - not used in our workflow
- file.md - superseded by other.md
## Refresh Instructions
1. Check upstream repo
2. Compare SKILL.md sections against local
3. Compare each reference file against local versions
4. Preserve custom additions listed above when merging
## Applying Updates
(process notes, version-pin reasoning)
Why this schema beats simple metadata:
It's a fork ledger. Every skill is treated as a fork of someone else's mental model, and the receipts make the fork auditable. You can answer "why is this skill here, and why is it different from the upstream?" in 30 seconds.
Updates without amnesia. Refresh Instructions tell future-you how to pull upstream changes without losing the local tuning. When upstream rewrites in a way I reject, I can take the additive changes and skip the rewrite. The decision is preserved in the file.
Conflicts surfaced, not buried. Custom Additions and Excluded sections answer "why is this different from the upstream?" without a three-way diff.
I haven't seen anyone else doing this. If you have, send me the link. I'd rather not be the only one.
How I generate new skills
Two skills, run in order. Skipping the first produces bad skills.
I always start with the brainstorming skill. It's mandatory before any creative work in my workflow. Brainstorming refines the rough idea, surfaces alternatives I didn't think of, and stress-tests the premise with questions like "when would you NOT want this to fire?" What comes out is an aligned design, not a half-baked skill.
Then I run skill-creator. It handles the scaffolding once the design is locked: frontmatter, file structure, the description string the trigger matcher uses, the YAML metadata. Skill-creator doesn't make design decisions. It packages the decisions brainstorming already made.
The discipline matters. I don't generate skills on impulse anymore. The brainstorm step kills the bad ones before they're written.
If I'd had this pipeline a year earlier, the gif-creator skill from the opener would never have made it into my .claude/. Brainstorming would have asked "when do you want this to fire?" and I would have answered "never." That's a skill I would not have kept.
Selective install, an origin.md next to every keep, brainstorm-then-create when I'm writing my own. That's the implementation.
Wild stuff that I never thought I'd be building.
Frequently asked questions
Should I delete every skill I'm not using?
No. Move them to status: trial in the origin.md (or just leave the origin.md untouched and don't invoke the skill). Some skills are dormant for a reason. Seasonal work, project-specific work, skills you'll need once a quarter. The point is to know why each one is there, not to run a continuous purge.
Does this scale to a team?
Probably yes, but I'm a solo practitioner. The origin.md pattern would need a shared catalog and a review cadence to work for a team. Untested. If you've tried it on a team, send me what worked and what didn't.
What about skills that don't have a clear single source?
If you wrote it yourself, set source: self and explain in the body. Self-authored skills are the easiest to audit because you wrote the rationale at the time. The catch is writing it AT the time, not three months later when you've forgotten.
Why not just disable plugins per-use instead of installing selectively?
Skills trigger on phrases, not on enable/disable state in most setups. Once installed, a skill can fire even if you forgot you installed it. That's the gif-creator failure mode from the opener. Selective install plus origin.md makes "did I want this here?" answerable. Disable doesn't.
What this is and isn't
This isn't a finished system. It's the curation method I'm running right now. 71 skills, 30 forks with receipts, 20 public unchanged, 21 written from scratch. One custom plugin tool. One origin.md schema. One brainstorm-then-create pipeline.
The framework is selective import plus per-skill provenance. The rest is implementation. If you're running 100+ skills and finding ones firing at moments you didn't expect, the receipts are the missing piece.
If you've found a different approach, I'd rather know than not. My DMs are open.